FUN2MODEL Research Themes:
Safety, Robustness, Optimality and Fairness Guarantees
« Overview
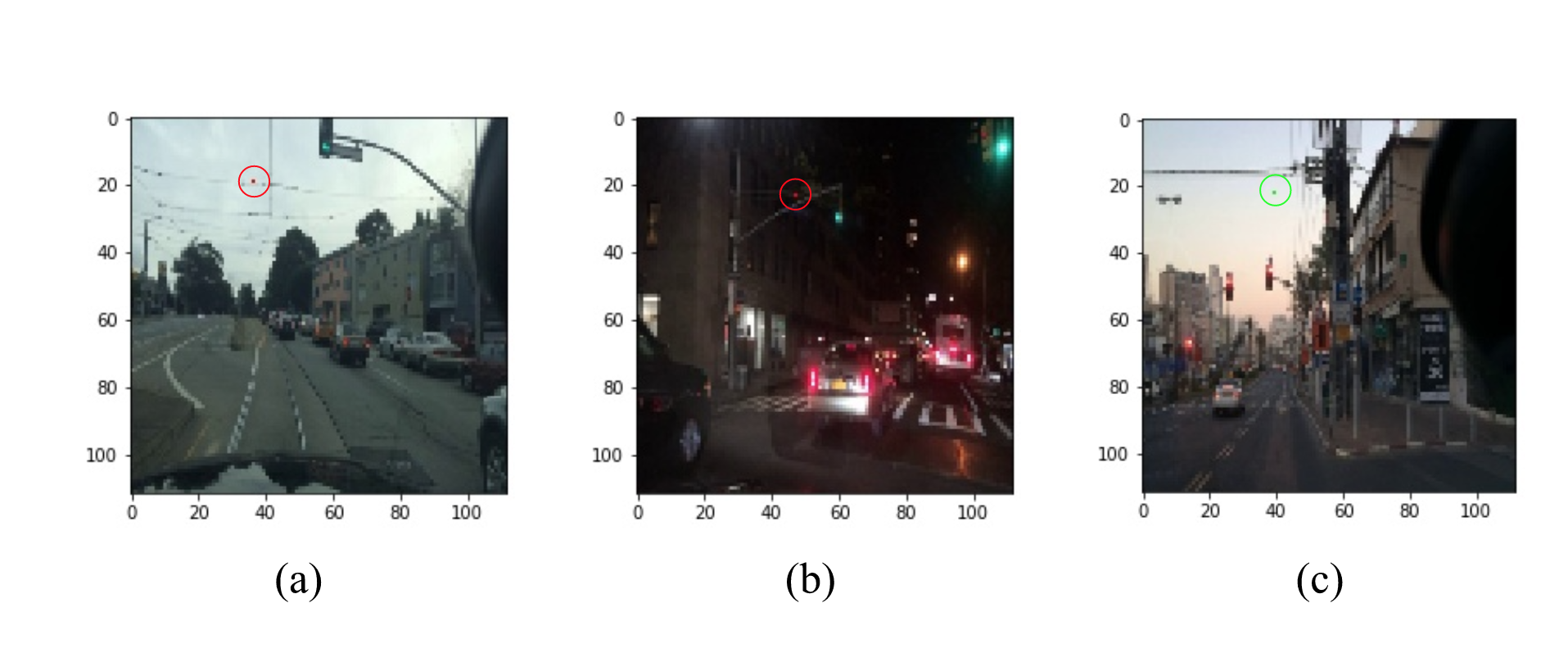
Adversarial examples. Neural networks lack robustness.
Machine learning – the science of building systems from data – is revolutionising computer science and artificial intelligence (AI). Much of its success is due to deep neural networks, which have demonstrated outstanding performance in perception tasks such as image classification. Solutions based on deep learning are now being deployed in a multitude of real-world systems, from virtual personal assistants, through automated decision making in business, to self-driving cars.
Deep neural networks have good generalisation properties, but are unstable with respect to so called adversarial examples, where a small, intentional input perturbation causes a false prediction, often with high confidence. Adversarial examples are still poorly understood but attracting attention because of the potential risks to safety and security in applications.
The image shows a traffic light correctly classified by a convolutional neural network, which is then misclassified after changing only a few pixels. This illustrative example, though somewhat artificial, since in practice the controller would rely on additional sensor input when making a decision, highlights the need for appropriate mechanisms and frameworks to prevent the occurrence of similar robustness issues during deployment.
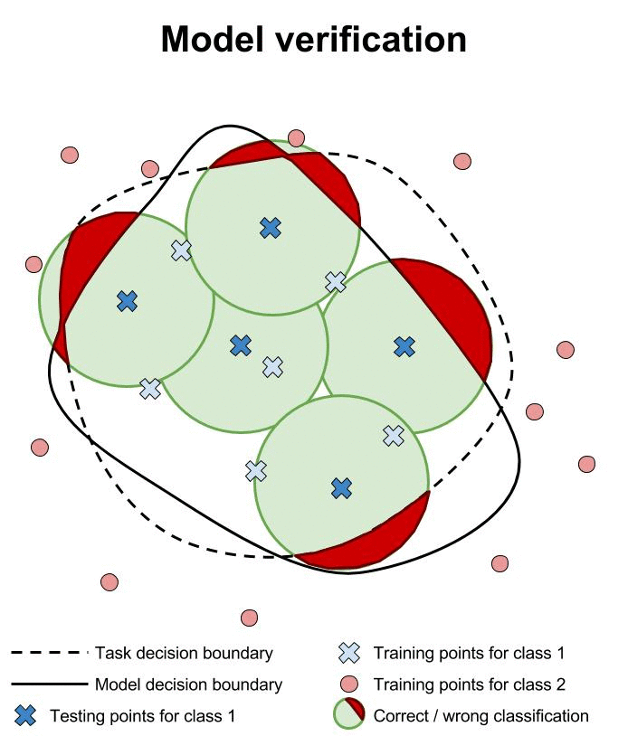
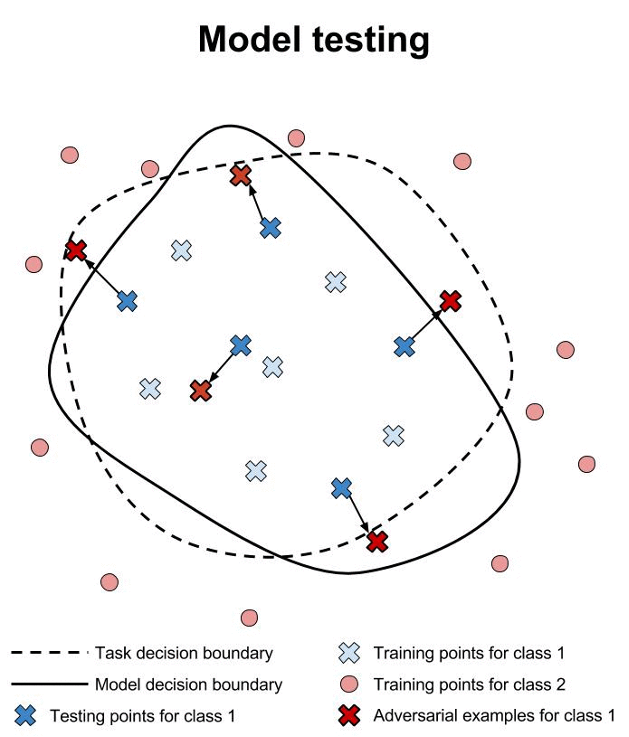
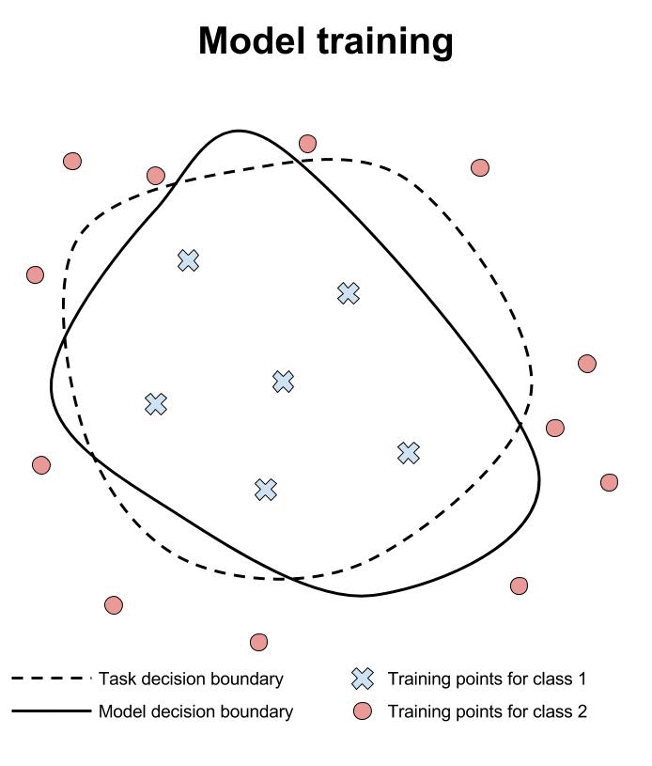
Safety verification for neural networks with provable guarantees. Maximum safe radius.
We have developed a game-based method for formal verification of deep neural networks. In contrast to heuristic search for adversarial examples, verification approaches aim to provide formal guarantees on the robustness of neural network models. This is illustrated above, where we contrast training, testing and verification (images from www.cleverhans.io).
We work with the maximum safe radius problem, which for a given input sample computes the minimum distance to an adversarial example, and demonstrate that, under the assumption of Lipschitz continuity, this problem can be approximated using finite optimisation by discretising the input space, and the approximation has provable guarantees, i.e., the error is bounded. We then show that the resulting optimisation problem can be reduced to the solution of a two-player turn-based game, where the first player selects features and the second perturbs the image within the feature. The method is anytime, in the sense of approximating the value of a game by monotonically improving its upper and lower bounds. We evaluate the method on images and also extend it to videos, where input perturbations are performed on optical flows.
Software:
DeepGame 
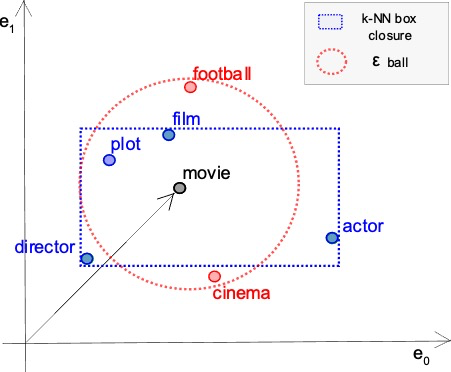
Robustness and explainability of natural language processing (NLP) models. Explanations may fail to be robust.
We study adversarial robustness of NLP models using maximal safe radius computation in the embedding space and formulate a framework for evaluating semantic robustness. We also build on abduction-based explanations for machine learning and develop a method for computing local explanations for neural network models in NLP. These explanations comprise a subset of the words of the input text that satisfies two key features: optimality with respect to a user-defined cost function, such as the length of explanation, and robustness, in that they ensure prediction invariance for any bounded perturbation in the embedding space of the left-out words. Our method can be configured with different perturbation sets in the embedded space (the image shows an example of perturbations in the k-NN neighbourhood and a standard norm ball) and used to detect bias in predictions.
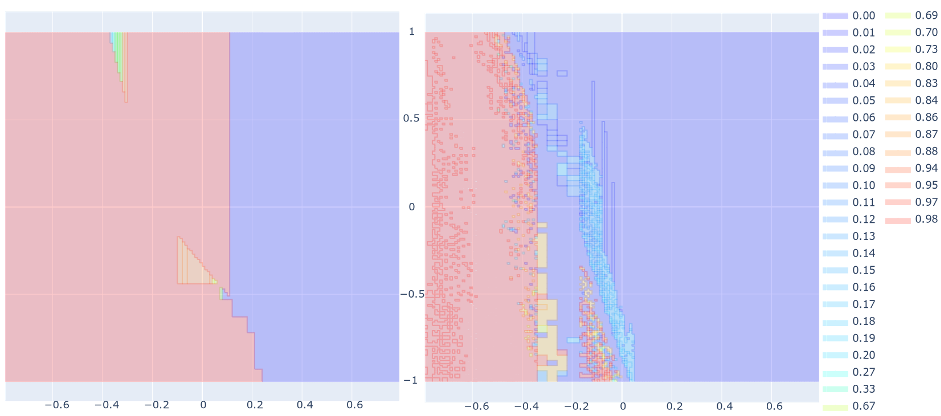
Safe deep reinforcement learning.
We have developed novel techniques for formally verifying the safe execution of deep reinforcement learning systems. These systems are stochastic due to the possibility of faults, noise or randomised policies, so we synthesise probabilistic guarantees which bound the likelihood of an unsafe state being reached within a specified horizon. To tackle the challenges of continuous state spaces and neural network policy representations, we develop automated methods that construct abstractions as finite Markov processes and then verify them using an extension of PRISM with support for interval-based probabilistic models.
The image shows heatmaps of failure probability upper bounds for subregions of initial states for the pendulum benchmark (x/y-axis: pole angle/angular velocity). Left: the initial abstraction; Right: the abstraction after 50 refinement steps.
Software:
SafeDRL
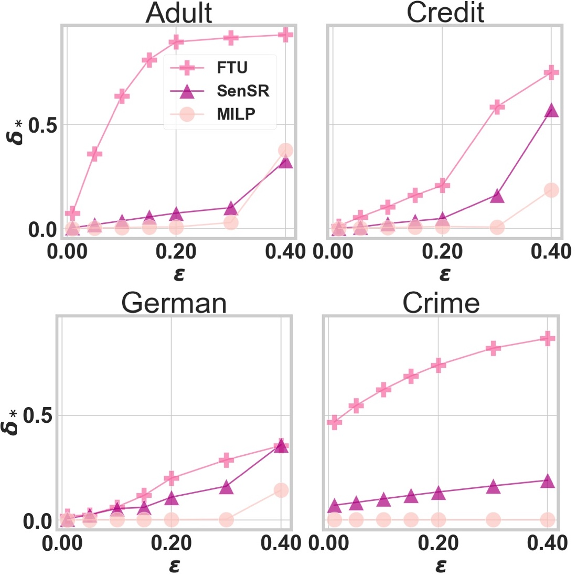
Individual fairness guarantees. Certifiable guarantees.
We study certification of fairness for neural networks. Rather than focusing on group fairness, we consider individual fairness, where the decision for any pair of similar individual should be bounded by a maximum decision tolerance. Working with a range of metrics, including the Mahalanobis distance, we propose a method to over-approximate the resulting optimisation problem using piecewise-linear functions to lower and upper bound the neural network’s non-linearities globally over the input space. We encode this computation as the solution of a Mixed-Integer Linear Programming (MILP) problem and show how this formulation can be used to encourage models’ fairness at training time by modifying the loss function.
The image shows certified individual fairness (y axis) as a function of maximum similarity (x axis) on four benchmarks.

Preimage under- and over-approximation for neural networks. Quantitative verification.
Most methods for neural network verification focus on bounding the image, i.e., set of outputs for a given input set. This can be used to, for example, check the robustness of neural network predictions to bounded perturbations of an input. However, verifying properties concerning the preimage, i.e., the set of inputs satisfying an output property, requires abstractions in the input space. We present a general framework for preimage abstraction that produces under- and over approximations of any polyhedral output set. We evaluate our method on a range of tasks, demonstrating significant improvement in efficiency and scalability to high-input-dimensional image classification tasks compared to state-of-the-art techniques. Further, we showcase the application to quantitative verification, backward reachability for controllers and robustness to patch attacks.
The image illustrates the workflow for preimage under-approximation (shown in 2D for clarity). Given a neural network and output specification O, our algorithm generates an under-approximation to the preimage. Starting from the input region C, the procedure repeatedly splits the selected region into smaller subregions C1 and C2 with tighter input bounds, and then optimises the bounding and Lagrangian parameters to increase the volume and thus improve the quality of the under-approximation. The refined under-approximation is combined into a union of polytopes.

Optimality guarantees for reinforcement learning. Sample efficiency guarantees.
Linear Temporal Logic (LTL) is widely used to specify high-level objectives for system policies, and it is highly desirable for autonomous systems to learn the optimal policy with respect to such specifications. However, learning the optimal policy from LTL specifications is not trivial. We present a model-free reinforcement learning approach that efficiently learns an optimal policy for an unknown stochastic system, modelled using Markov Decision Processes. We propose a novel algorithm, which leverages counterfactual imagining on order to efficiently learn the optimal policy that maximizes the probability of satisfying a given LTL specification with optimality guarantees. To directly evaluate the learned policy, we adopt the probabilistic model checker PRISM to compute the probability of the policy satisfying such specifications.
The image shows the performance of our algorithm (pink) on Office World environment compared to state of the art.

Robustness of Large Language Models (LLMs) for code. Are they robust to semantics-preserving code mutations?
Understanding the reasoning and robustness of LLMS is critical for their reliable use in programming tasks. While recent studies have assessed LLMS’ ability to predict program outputs, most focus solely on the accuracy of those predictions, without evaluating the reasoning behind them. Moreover, it has been observed on mathematical reasoning tasks that LLMS can arrive at correct answers through flawed logic, raising concerns about similar issues in code understanding. In this work, we evaluate whether state-of-the-art LLMS with up to 8B parameters can reason about Python programs or are simply guessing. We apply four semantics-preserving code mutations: renaming variables, mirroring comparison expressions, swapping if-else branches, and converting for loops to while. We evaluated six LLMS and performed a human expert analysis using LIVECODEBENCH to assess whether the correct predictions are based on sound reasoning. We also evaluated prediction stability across different code mutations on LIVECODEBENCH and CRUXEVAL. Our findings show that LLMS trained for code produce correct predictions based on flawed reasoning for 10% to 50% of cases. Furthermore, LLMS often change predictions in response to our code mutations, indicating they do not yet exhibit stable, semantically grounded reasoning.
The image shows an example prompt provided to the LLM.
To know more about these models and analysis techniques, follow the links below.
Software:
DeepGame
SafeDRL
Related publications:
Sort by: date, type, title
40 publications:
-
[BZK25]
Anton Björklund, Mykola Zaitsev, Marta Kwiatkowska.
Efficient Preimage Approximation for Neural Network Certification.
Technical report 2505.22798, arxiv. Paper under submission.
2025.
[pdf]
[bib]
https://arxiv.org/abs/2505.22798
-
[OK25]
Pedro Orvalho and Marta Kwiatkowska.
Are Large Language Models Robust in Understanding Code Against Semantics-Preserving Mutations?.
Technical report , arXiv:2505.10443. Paper under submission.
2025.
[pdf]
[bib]
https://arxiv.org/abs/2505.10443
-
[BGMK25]
Thomas Kleine Buening, Jiarui Gan, Debmalya Mandal, Marta Kwiatkowska.
Strategyproof Reinforcement Learning from Human Feedback.
In Proc. 39th Annual Conference on Neural Information Processing Systems (NeurIPS'25). To appear.
2025.
[pdf]
[bib]
-
[OJM25]
Pedro Orvalho, Mikolas Janota, Vasco Manquinho.
Counterexample Guided Program Repair Using Zero-Shot Learning and MaxSAT-based Fault Localization.
In Proc. at Thirty-Ninth AAAI Conference on Artificial Intelligence (AAAI-25). To appear.
2025.
[pdf]
[bib]
https://arxiv.org/abs/2502.07786
-
[OK25b]
Pedro Orvalho and Marta Kwiatkowska.
PyVeritas: On Verifying Python via LLM-Based Transpilation and Bounded Model Checking for C.
In Workshop on Post-AI Formal Methods (AAAI-26, Singapore). Available as arXiv:2508.08171.
2025.
[pdf]
[bib]
https://arxiv.org/abs/2508.08171
-
[SAP25]
Yannik Schnitzer, Alessandro Abate and David Parker.
Certifiably Robust Policies for Uncertain Parametric Environments.
In Proc. 31st International Conference on Tools and Algorithms for the Construction and Analysis of Systems (TACAS'25), Springer.
2025.
[pdf]
[bib]
-
[ZWKZ25]
Xiyue Zhang, Benjie Wang, Marta Kwiatkowska, Huan Zhang.
PREMAP: A Unifying PREiMage APproximation Framework for Neural Networks.
Journal of Machine Learning Research (JMLR). To appear.
2025.
[pdf]
[bib]
https://arxiv.org/abs/2408.09262
-
[BCC+24]
Tomáš Brázdil, Krishnendu Chatterjee, Martin Chmelik, Vojtěch Forejt, Jan Křetínský, Marta Kwiatkowska, Tobias Meggendorfer, David Parker, Mateusz Ujma.
Learning Algorithms for Verification of Markov Decision Processes.
Technical report , arXiv:2403.09184. Paper under submission.
2024.
[pdf]
[bib]
https://arxiv.org/abs/2403.09184
-
[SFK24]
Daqian Shao, Lukas Fesser, Marta Kwiatkowska.
STR-Cert: Robustness Certification for Deep Text Recognition on Deep Learning Pipelines and Vision Transformers.
Technical report , arXiv:2401.05338. Paper under submission.
2024.
[pdf]
[bib]
https://arxiv.org/abs/2401.05338
-
[ZWK24]
Xiyue Zhang, Benjie Wang, Marta Kwiatkowska.
Provable preimage under-approximation for neural networks.
In Proc. 30th International Conference on Tools and Algorithms for the Construction and Analysis of Systems (TACAS 2024), Springer.
2024.
[pdf]
[bib]
-
[EPF24]
Ingy Elsayed-Aly, David Parker and Lu Feng.
Distributional Probabilistic Model Checking.
In Proc. 16th NASA Formal Methods Symposium (NFM'24), volume 14627 of LNCS, pages 57-75, Springer.
2024.
[pdf]
[bib]
-
[NR24]
Daniel Neider and Rajarshi Roy.
What Is Formal Verification Without Specifications? A Survey on Mining LTL Specifications.
In Jansen, N., et al. Principles of Verification: Cycling the Probabilistic Landscape. Lecture Notes in Computer Science, Springer.
2024.
[pdf]
[bib]
-
[SBB+24]
Marnix Suilen, Thom Badings, Eline M. Bovy, David Parker and Nils Jansen.
Robust Markov Decision Processes: A Place Where AI and Formal Methods Meet.
In Principles of Verification: Cycling the Probabilistic Landscape,, pages 126–154, Springer.
2024.
[pdf]
[bib]
-
[CWZS24]
Jialuo Chen, Jingyi Wang, Xiyue Zhang, Youcheng Sun, Marta Kwiatkowska, Jiming Chen, Peng Cheng.
FAST: Boosting Uncertainty-based Test Prioritization Methods for Neural Networks via Feature Selection.
In 39th IEEE/ACM International Conference on Automated Software Engineering (ASE 2024). To appear.
2024.
[pdf]
[bib]
https://arxiv.org/abs/2409.09130
-
[LKF24]
Tobias Lorenz, Marta Kwiatkowska, Mario Fritz .
FullCert: Deterministic End-to-End Certification for Training and Inference of Neural Networks.
In The German Conference on Pattern Recognition (GCPR), Springer Nature. To appear.
2024.
[pdf]
[bib]
-
[LWK23]
Emanuele La Malfa, Matthew Wicker, Marta Kwiatkowska.
Emergent Linguistic Structures in Neural Networks are Fragile.
Technical report , arXiv.
2023.
[pdf]
[bib]
https://arxiv.org/abs/2210.17406
-
[Lam23]
Emanuele La Malfa.
On Robustness for Natural Language Processing.
Ph.D. thesis, Department of Computer Science, University of Oxford.
2023.
[pdf]
[bib]
-
[LKF23]
Tobias Lorenz, Marta Kwiatkowska and Mario Fritz.
Certifiers Make Neural Networks Vulnerable to Availability Attacks.
In 16th ACM Workshop on Artificial Intelligence and Security (AISec 2023). To appear.
2023.
[pdf]
[bib]
-
[KZ23]
Marta Kwiatkowska, Xiyue Zhang.
When to Trust AI: Advances and Challenges for Certification of Neural Networks.
In Proceedings of the 18th Conference on Computer Science and Intelligence Systems (FedCSIS 2023). To appear.
2023.
[pdf]
[bib]
-
[Kwi23]
Marta Kwiatkowska.
Robust Decision Pipelines: Opportunities and Challenges for AI in Business Process Modelling.
In BPM 2023 Forum, Utrecht, The Netherlands, A Springer Nature Computer Science book series. To appear.
2023.
[pdf]
[bib]
-
[SK23]
Daqian Shao, Marta Kwiatkowska.
Sample Efficient Model-free Reinforcement Learning from LTL Specifications with Optimality Guarantees.
In Proc. 32nd International Joint Conference on Artificial Intelligence (IJCAI'23).
2023.
[pdf]
[bib]
-
[WZZS23]
Zeming Wei, Xiyue Zhang, Yihao Zhang, Meng Sun.
Weighted Automata Extraction and Explanation of Recurrent Neural Networks for Natural Language Tasks.
Journal of Logical and Algebraic Methods in Programming, Elsevier.
2023.
[pdf]
[bib]
-
[BRA+23]
Thom Badings, Licio Romao, Alessandro Abate, David Parker, Hasan A. Poonawala, Marielle Stoelinga and Nils Jansen.
Robust Control for Dynamical Systems with Non-Gaussian Noise via Formal Abstractions.
Journal of Artificial Intelligence Research, 76, pages 341-391.
January 2023.
[pdf]
[bib]
-
[PK22]
Aleksandar Petrov, Marta Kwiatkowska.
Robustness of Unsupervised Representation Learning without Labels.
Technical report arXiv:2210.04076, arXiv.
2022.
[pdf]
[bib]
https://doi.org/10.48550/arXiv.2210.04076
-
[PBL+22]
Andrea Patane, Arno Blaas, Luca Laurenti, Luca Cardelli, Stephen Roberts and Marta Kwiatkowska.
Adversarial Robustness Guarantees for Gaussian Processes.
Journal of Machine Learning Research, 23, pages 1-55.
2022.
[pdf]
[bib]
-
[SSJP22]
Marnix Suilen, Thiago D. Simão, Nils Jansen and David Parker.
Robust Anytime Learning of Markov Decision Processes.
In Proc. 36th Annual Conference on Neural Information Processing Systems (NeurIPS'22).
November 2022.
[pdf]
[bib]
-
[BPW+22]
Elias Benussi, Andrea Patane, Matthew Wicker, Luca Laurenti and Marta Kwiatkowska.
Individual Fairness Guarantees for Neural Networks.
In Proc. 31st International Joint Conference on Artificial Intelligence (IJCAI'22). To appear.
July 2022.
[pdf]
[bib]
-
[BP22]
Edoardo Bacci and David Parker.
Verified Probabilistic Policies for Deep Reinforcement Learning.
In Proc. 14th International Symposium NASA Formal Methods (NFM'22), volume 13260 of LNCS, pages 193-212, Springer.
May 2022.
[pdf]
[bib]
-
[LK22]
Emanuele La Malfa and Marta Kwiatkowska.
The King is Naked: on the Notion of Robustness for Natural Language Processing.
In Proc. 36th AAAI Conference on Artificial Intelligence (AAAI'22). To appear.
March 2022.
[pdf]
[bib]
-
[BAJ+22]
Thom S. Badings, Alessandro Abate, Nils Jansen, David Parker, Hasan A. Poonawala and Marielle Stoelinga.
Sampling-Based Robust Control of Autonomous Systems with Non-Gaussian Noise.
In Proc. 36th AAAI Conference on Artificial Intelligence (AAAI'22).
March 2022.
[pdf]
[bib]
-
[Bac22]
Edoardo Bacci.
Formal Verification of Deep Reinforcement Learning Agents.
Ph.D. thesis, School of Computer Science, University of Birmingham.
March 2022.
[pdf]
[bib]
-
[LWL+20]
Emanuele La Malfa, Min Wu, Luca Laurenti, Benjie Wang, Anthony Hartshorn and Marta Kwiatkowska.
Assessing Robustness of Text Classification through Maximal Safe Radius Computation.
In Conference on Empirical Methods in Natural Language Processing (EMNLP'20), ACL.
November 2020.
[pdf]
[bib]
-
[BP20]
Edoardo Bacci and David Parker.
Probabilistic Guarantees for Safe Deep Reinforcement Learning.
In 18th International Conference on Formal Modelling and Analysis of Timed Systems (FORMATS'20), Springer.
September 2020.
[pdf]
[bib]
-
[BPL+20]
Arno Blaas, Andrea Patane, Luca Laurenti, Luca Cardelli, Marta Kwiatkowska and Stephen Roberts.
Adversarial Robustness Guarantees for Classification with Gaussian Processes.
In 23rd International Conference on Artificial Intelligence and Statistics (AISTATS'20), PMLR.
August 2020.
[pdf]
[bib]
-
[WK20]
Min Wu and Marta Kwiatkowska.
Robustness Guarantees for Deep Neural Networks on Videos.
In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR'20), IEEE.
June 2020.
[pdf]
[bib]
-
[Wu20]
Min Wu.
Robustness Evaluation of Deep Neural Networks with Provable Guarantees.
Ph.D. thesis, Department of Computer Science, University of Oxford.
May 2020.
[pdf]
[bib]
Sort by: date, type, title
« Overview

