

Horizon 2020

The deployment of autonomous robots of autonomous robots promises to improve human lifespan, productivity and well-being. However, successful integration of these robots into our society is challenging, as demonstrated by a fatal crash involving Tesla thought to be caused by the driver placing excessive trust in the vehicle. Ensuring smooth, safe and beneficial collaboration between humans and robots will require machines to understand our motivations and complex mental attitudes such as trust, guilt or shame, and be able to mimic them. Robots can take an active role in reducing misuse if they are able to detect human biases, inaccurate beliefs or overtrust, and make accurate predictions of human behaviour.
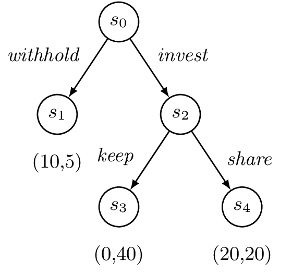
This work investigates a cognitive extension of stochastic multiplayer games, a novel parametric framework for multi-agent human-like decision making, which aims to capture human motivation through mental, as well as physical, goals. Additionally, limitations of human reasoning are captured via a parameterisation of each agent, which also allows us to represent the wide variety of people’s personalities. Mental shortcuts homo sapiens employ to make sense of the complexity of the external environment are captured by equipping agents with heuristics. Our framework enables expression of cognitive notions such as trust in terms of beliefs, whose dynamics is affected by agent’s observation of interactions and own preferences.
Along with the theoretical model, we provide a tool, implemented using probabilistic programming, that allows one to specify cognitive models, simulate their execution, generate quantitative behavioural predictions and learn agent characteristics from data.
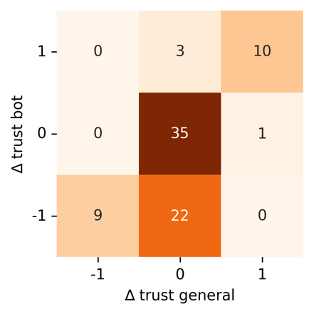
We have designed and conducted an experiment that has human participants playing the classical Trust Game [https://www.frontiersin.org/articles/10.3389/fnins.2019.00887/full] against a custom bot whose decision making is driven by our cognitive stochastic game framework. The roles of investor and investee are assigned at random, and the bot is able to play in either. Results show that predictions of human behaviour generated by the framework are on par with, and in some circumstances superior to, the state of the art. Moreover, our study demonstrates that using an informed prior about the participants’ preferences and cognitive abilities, collected through a simple questionnaire, can significantly improve the accuracy of behavioural predictions. Further, we find evidence for subjects overtrusting the bot, confirming what has been hypothesised for Tesla drivers. On the other hand, the vast majority of participants displayed a high degree of opportunism when interacting with the bot, suggesting machines are not treated on an equal footing.
The image depicts a confusion matrix showing how change of trust towards the bot (y axis) translates into trust change towards robots generally (x axis). Values −1, 0 and 1 represent participants reporting a decrease, no change and an increase of trust, respectively. The data (Amazon Mechanical Turk) is available here.
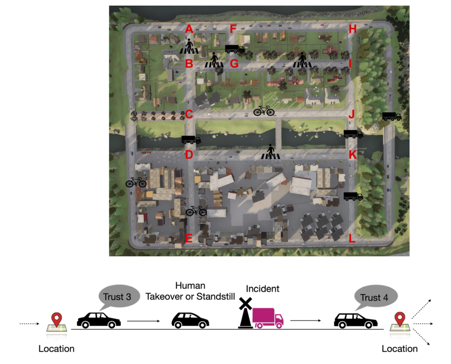
Collaborative human-robot partnerships often hinge on the foundation of trust. Therefore, recognizing human trust and incorporating it into the decision-making process is essential for achieving the full potential of human-robot interactive systems. Since human trust in robots is not observable, we adopt the widely used partially observable Markov decision process framework for modelling the interactions between humans and robots. To specify the desired behaviour, we propose to use syntactically co-safe linear distribution temporal logic, a logic that is defined over predicates of states as well as belief states of partially observable systems, which presents new challenges as the belief predicates must be evaluated over the continuous (infinite) belief space. To address this challenge, we present an algorithm for solving the optimal policy synthesis problem. Human subject experiments with 21 participants on a driving simulator demonstrate the effectiveness of the proposed approach.
The image shows a route planning scenario for AVs. On top is a map with three types of road incidents (pedestrian, obstacle, and oncoming truck). The bottom part depicts a schematic view of the decision-making process.

Online planning for partially observable Markov decision processes provides efficient techniques for robot decision-making under uncertainty. However, existing methods fall short of preventing safety violations in dynamic environments. We investigate safe online planning for a robotic agent travelling among multiple unknown dynamic agents, such as pedestrians or other robots. We consider a safety constraint, which specifies that the minimum distance from the robotic agent to any of the dynamic agents should exceed a predefined safety buffer. The goal is to develop a safe online planning method that computes an optimal policy maximizing the expected return while ensuring that the probability of satisfying the safety constraint exceeds a certain threshold. Our approach utilizes data-driven trajectory prediction models of dynamic agents and applies Adaptive Conformal Prediction (ACP) to quantify the uncertainties in these predictions.
The image shows different scenarios, on which we applied our method.

Consider an agent acting to achieve its temporal goal, but with a “trembling hand”. In this case, the agent may mistakenly instruct, with a certain (typically small) probability, actions that are not intended due to faults or imprecision in its action selection mechanism, thereby leading to possible goal failure. We study the trembling-hand problem in the context of reasoning about actions and planning for temporally extended goals expressed in Linear Temporal Logic on finite traces,where we want to synthesize a strategy that maximizes the probability of satisfying the goal in spite of the trembling hand. We work with both deterministic and nondeterministic (adversarial) domains. We propose solution techniques for both cases and demonstrate their effectiveness experimentally through a proof-of-concept implementation.
The image shows an optimal strategy generated for a human-robot co-assembly problem, where the robot with a “trembling hand” aims to assemble an arch from blocks along with a human in a shared workspace. During assembly, the robot can perform actions to relocate blocks, and the human may perform moves to intervene. Robot-intended actions, robot-executed actions, and human interventions are shown in black, brick, and blue, respectively.
To know more about these models and analysis techniques, follow the links below.
Software:CognitiveAgents 